Using pg_repack in AWS RDS
As your database keeps growing, there is a good chance you're going to have to address database bloat.
While Postgres 13 has launched with some exciting features with built-in methods to rebuild indexes concurrently, many people still end up having to use pg_repack to do an online rebuild of the tables to remove the bloat. Customers on AWS RDS struggle figuring out how to do this. Ready to learn how?
Since you have no server to access the local binaries, and because AWS RDS provides no binaries for the versions they are using, you're going to have to build your own. This isn't as hard as one might think because the official pg repos have an installer (ie: sudo apt install postgresql-10-pg_repack). If you don't use the repos, the project itself, is an open source project with directions: http://reorg.github.io/pg_repack/
While you were getting up to speed above, I was spinning up a postgres 10.9 db on RDS. I started it yesterday so that it would be ready by the time you got to this part of the post. Lets create some data:
-- let's create the table
CREATE TABLE burritos (
id SERIAL UNIQUE NOT NULL primary key,
title VARCHAR(10) NOT NULL,
toppings TEXT NOT NULL,
thoughts TEXT,
code VARCHAR(4) NOT NULL,
UNIQUE (title, toppings)
);
--disable auto vacuum
ALTER TABLE burritos SET (autovacuum_enabled = false, toast.autovacuum_enabled = false);
-- orders up
INSERT INTO burritos (title, toppings, thoughts, code)
SELECT
left(md5(i::text), 10),
md5(random()::text),
md5(random()::text),
left(md5(random()::text), 4)
FROM GENERATE_SERIES(1, 1000000) s(i);
UPDATE burritos SET toppings = md5(random()::text) WHERE id < 250;
UPDATE burritos SET toppings = md5(random()::text) WHERE id between 250 and 500;
UPDATE burritos SET code = left(md5(random()::text), 4) WHERE id between 2050 and 5000;
UPDATE burritos SET thoughts = md5(random()::text) WHERE id between 10000 and 20000;
UPDATE burritos SET thoughts = md5(random()::text) WHERE id between 800000 and 900000;
UPDATE burritos SET toppings = md5(random()::text) WHERE id between 600000 and 700000;(If you are curious how Magistrate presents bloat, here is a clip of the screen:)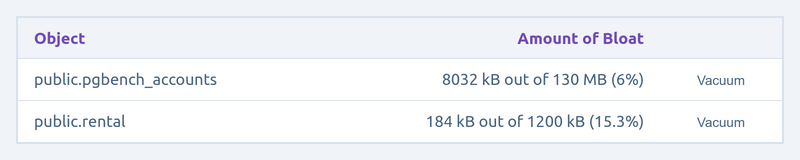
Much like a human that has had that much interaction with burritos... our database has quite a bit of bloat. Assuming we already have the pg_repack binaries in place, either though compilation or installing the package on the OS, we now need to enable the extension. We've put together a handy reference for installing extensions to get you going.
pg_repack has a lot of options. Feel free to check them out, but I'm going to start packing:
/usr/local/bin/pg_repack -U greataccounthere -h bloatsy.csbv99zxhbsh.us-east-2.rds.amazonaws.com -d important -t burritos -j 4
NOTICE: Setting up workers.conns
ERROR: pg_repack failed with error: You must be a superuser to use pg_repackThis might feel like game over because of the implementation of superuser on RDS, but the trick is to take a leap of faith and add another flag (-k) that skips the superuser check:
/usr/local/bin/pg_repack-1.4.3/pg_repack -U greataccounthere -h bloatsy.csbv99zxhbsh.us-east-2.rds.amazonaws.com -k -d important -t burritos -j 4
NOTICE: Setting up workers.conns
INFO: repacking table "public.burritos"
LOG: Initial worker 0 to build index: CREATE UNIQUE INDEX index_16449 ON repack.table_16442 USING btree (id) TABLESPACE pg_default
LOG: Initial worker 1 to build index: CREATE UNIQUE INDEX index_16451 ON repack.table_16442 USING btree (title, toppings) TABLESPACE pg_default
LOG: Command finished in worker 0: CREATE UNIQUE INDEX index_16449 ON repack.table_16442 USING btree (id) TABLESPACE pg_default
LOG: Command finished in worker 1: CREATE UNIQUE INDEX index_16451 ON repack.table_16442 USING btree (title, toppings) TABLESPACE pg_defaultIt works! The table is feeling fresh and tidy and your application has a little more pep in its step. When using Magistrate our platform matrix also knows when you have pg_repack installed and gives you the commands to run for tables it detects with high bloat percentage.
Make Your Postgres Database Faster
Sign up for early access and gain insights on slow queries, bloat, and missing/unused indexes.